일반적으로 머신러닝 모델을 개발하고 배포하는 과정은 다음과 같습니다.
1. 데이터 수집 / 가공 / 검증
2. 모델 선정 및 학습
3. 모델 검증 및 평가
4. 배포 및 관리
SageMaker 란?
AWS Sagemaker는 클라우드 머신러닝 도구로 User가 손쉽게 머신러닝 모델을 구축, 학습, 튜닝, 배포하게 도와주는 완전관리형 서비스입니다. Sagemkaer는 최적화된 다수의 머신러닝 알고리즘이 내장되어있으며 이를 손쉽게 활용도 가능합니다.
이번 글에서는 Sagemaker로 모델을 훈련하고 훈련된 모델을 배포하는 간단한 실습에 대해서 정리해보았습니다.
실습환경 구성
본 실습을 진행하기위해선 다음과 같은 전제조건이 필요합니다.
- Cloud9 : 클라우드 기반 통합 개발 환경(IDE, Integrated Development Environment)
- Sagemaker(Jupyter Notebook) : 관리형 Jupyter Notebook 환경
- Lambda : 서버리스(Serverless) 컴퓨팅 서비스, 서버 관리없이 코드 실행 가능
심장마비 예측 모델
추론 내용
로지스틱 회귀 모델을 훈련시키고 심장마비 가능성을 예측
완성된 모델은 주어진 데이터를 입력받아 심장마비 가능성이 낮으면 0, 높으면 1을 리턴합니다.
모델 훈련에 사용할 데이터는 캐글(Kaggle)에서 Heart Attack Analysis & Prediction Dataset 을 사용합니다.
실습의 전체적인 과정은 다음과 같습니다.
- 필요한 패키지를 불러옵니다.
- 데이터를 처리합니다.
- SageMaker Notebook 인스턴스를 사용하여 모델을 훈련합니다.
- 훈련된 모델을 엔드포인트로 배포합니다.
실습
1. SageMaker Notebook 인스턴스 생성

데이터 처리, 모델 훈련, 모델 배포에 필요한 패키지를 import합니다.
- 데이터 처리: 사이킷런(scikit-learn), numpy
- 모델 훈련 및 배포: sagemaker
import sagemaker
from sagemaker.sklearn.model import SKLearnModel # 사이킷런 모델을 SageMaker에서 사용할 수 있게 해주는 도구
from sagemaker import get_execution_role # SageMaker가 필요한 권한을 가져오는 함수
import numpy as np
CSV 파일에서 데이터를 읽어옵니다. 읽어온 데이터를 numpy 배열(2차원)로 변환합니다.
전체 데이터를 훈련용 데이터와 테스트용 데이터로 나누고 각 데이터셋에서 특성(입력 변수)과 레이블(예측하고자 하는 목표 변수)을 분리합니다.
# CSV 파일을 읽어서 숫자 배열로 만들어 반환
rawdata = np.genfromtxt("heart.csv", delimiter=',', skip_header=1)
# 일반적으로 전체 데이터의 80%를 훈련 용도로, 나머지는 테스트 용도로 사용
train_size = int(len(rawdata) * 0.8)
train = rawdata[:train_size]
test = rawdata[train_size:]
# 훈련 데이터를 입력(X)과 결과(Y)로 구분
Xtr = train[:, :-1] # 마지막 열을 제외한 모든 열(특성들, features)
Ytr = train[:, -1] # 마지막 열(예측하려는 값, target variables)
# Python 배열 슬라이싱은 아래 데이터로 연습
# test_list = [
# [1, 2, 3, 0],
# [4, 5, 6, 1],
# [7, 8, 9, 0]]
# 테스트 데이터를 입력(X)과 결과(Y)로 구분
Xts = test[:, :-1]
Yts = test[:, -1]
SageMaker의 내장 알고리즘(Built-In Algorithms) 중 로직스틱 회귀 모델을 설정합니다. 훈련을 위해 ml.m5.xlarge(4 vCPUs, 16 GiB RAM) 인스턴스를 사용합니다.
훈련에 알맞는 데이터를 RecordIO Protobuf 형식으로 변환하고 준비된 데이터로 모델을 훈련시킵니다.
SageMaker Amazon은 데이터 과학자와 기계 학습 전문가가 기계 학습 모델을 빠르게 교육 및 배포할 수 있도록 기본 제공 알고리즘, 사전 학습된 모델, 사전 구축된 솔루션 템플릿 제품군을 제공합니다. 아래 링크에서 SageMaker 에 내장된 알고리즘을 확인할 수 있습니다.
[SageMaker Built-In Algorithms]
Built-in Algorithms — sagemaker 2.232.1 documentation
2. SageMaker Notebook 인스턴스를 사용하여 모델을 훈련하고 엔드포인트로 배포
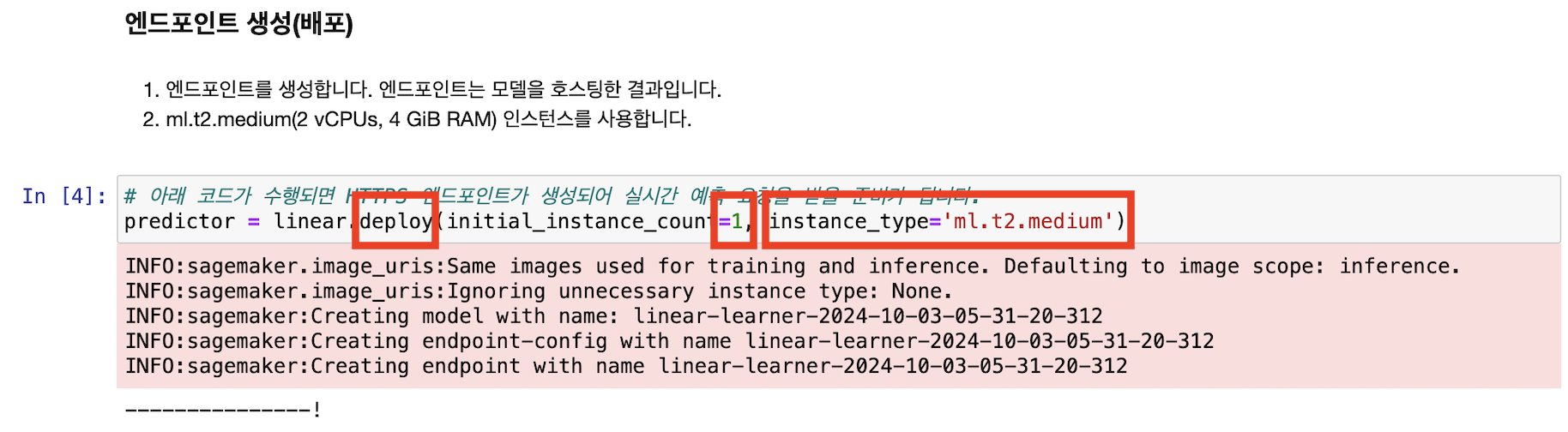
엔드포인트를 생성합니다. 엔드포인트는 모델을 호스팅한 결과입니다. (ml.t2.medium(2 vCPUs, 4 GiB RAM) 인스턴스를 사용)
아래 메시지가 순차적으로 나타나며 훈련이 진행되고 훈련이 완료되면 배포(엔드포인트 생성)가 진행됩니다.
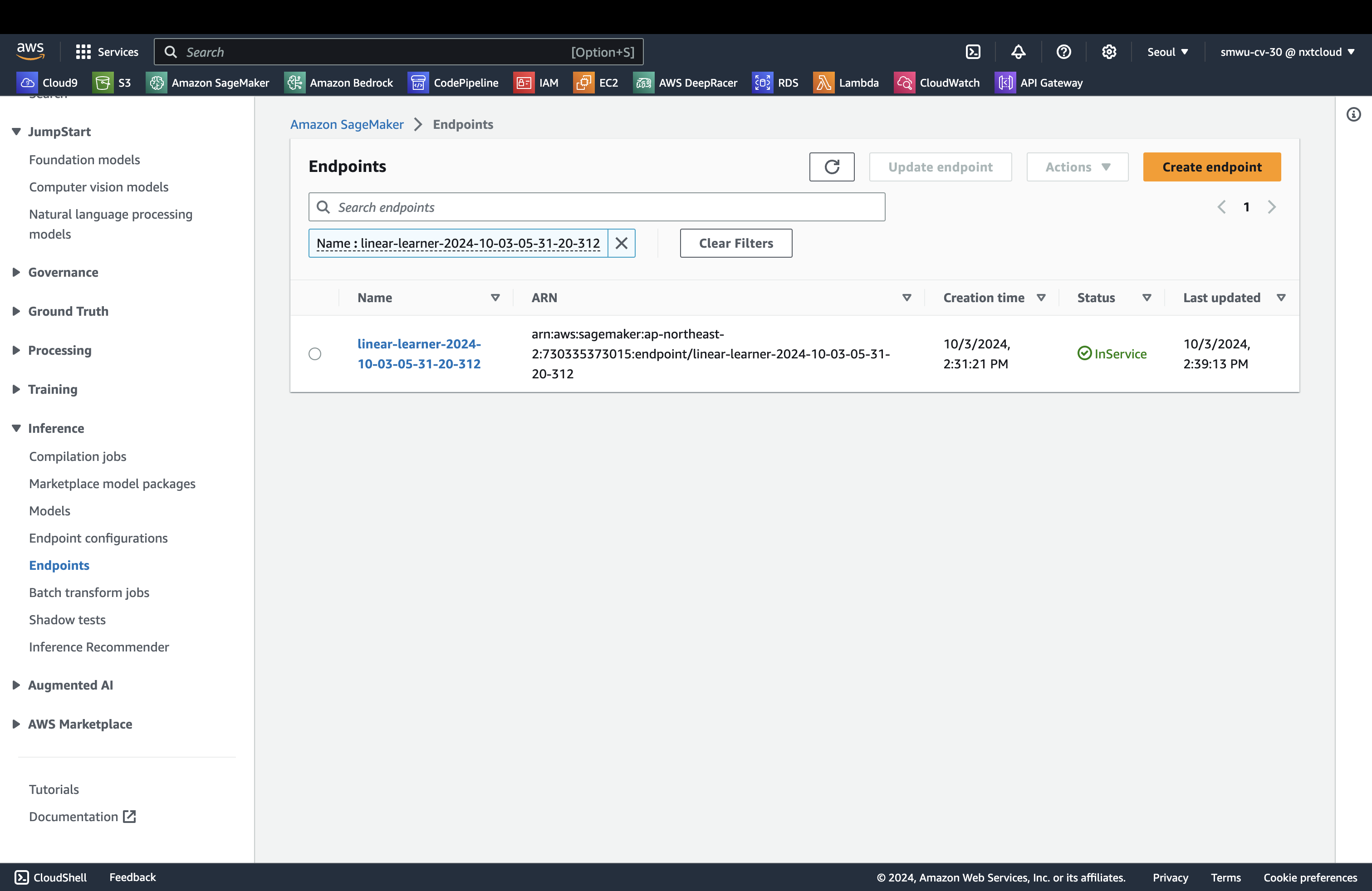
SageMaker 페이지에서 Inference 아래 Endpoints 클릭하면 배포가 진행 중인 것을 확인할 수 있습니다.
InService 가 뜨면서 배포가 완료되어 엔드포인트가 생성된 것을 확인할 수 있습니다.
3. 엔드포인트로 JSON을 body와 함께 POST 요청을 보내서 모델을 추론
관리 콘솔에서 Lambda 페이지로 이동 후 함수 생성(Create function) 버튼 클릭하여 Sagemaker를 호출하는 Lambda Function을 생성합니다.
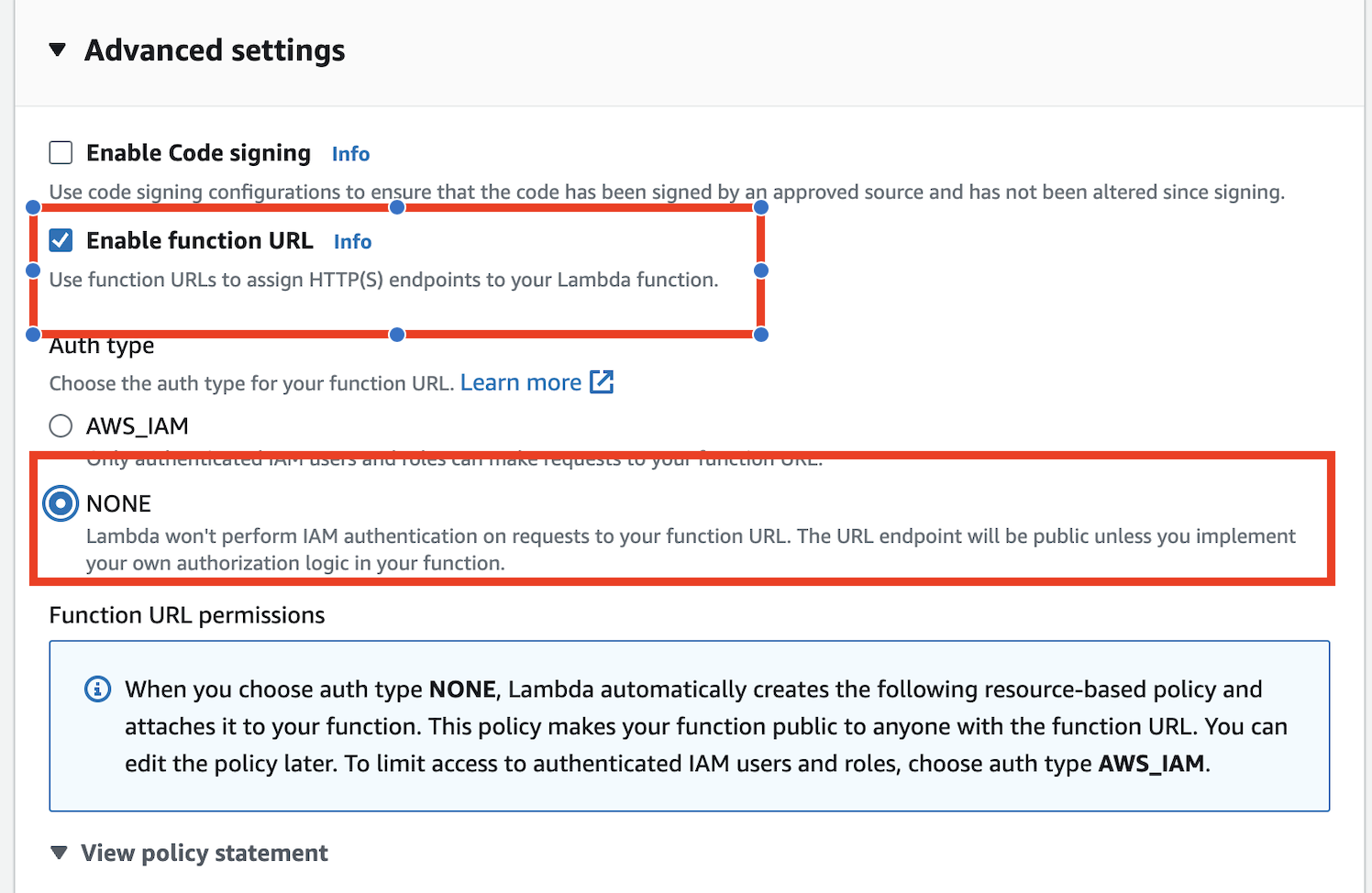
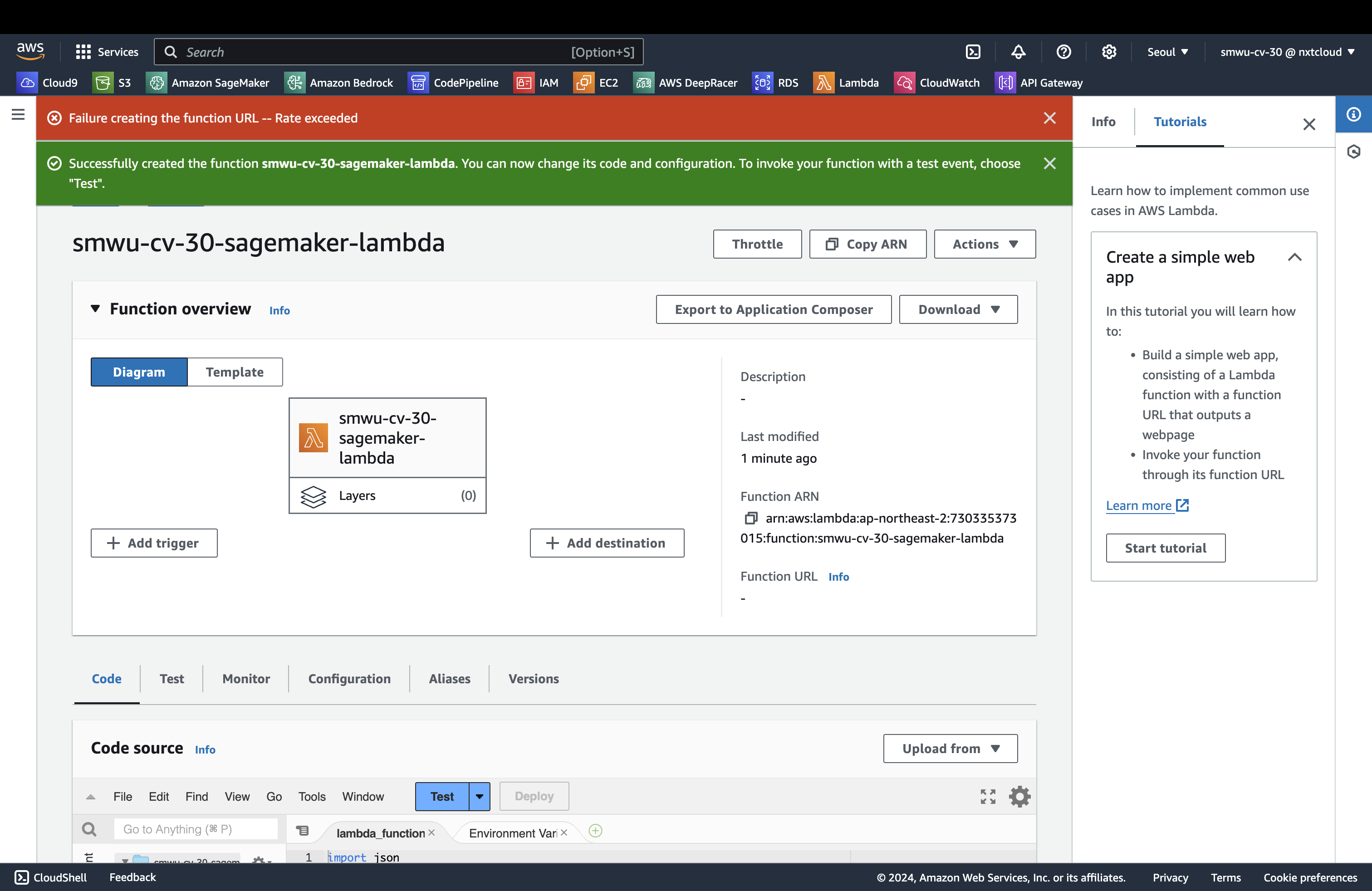
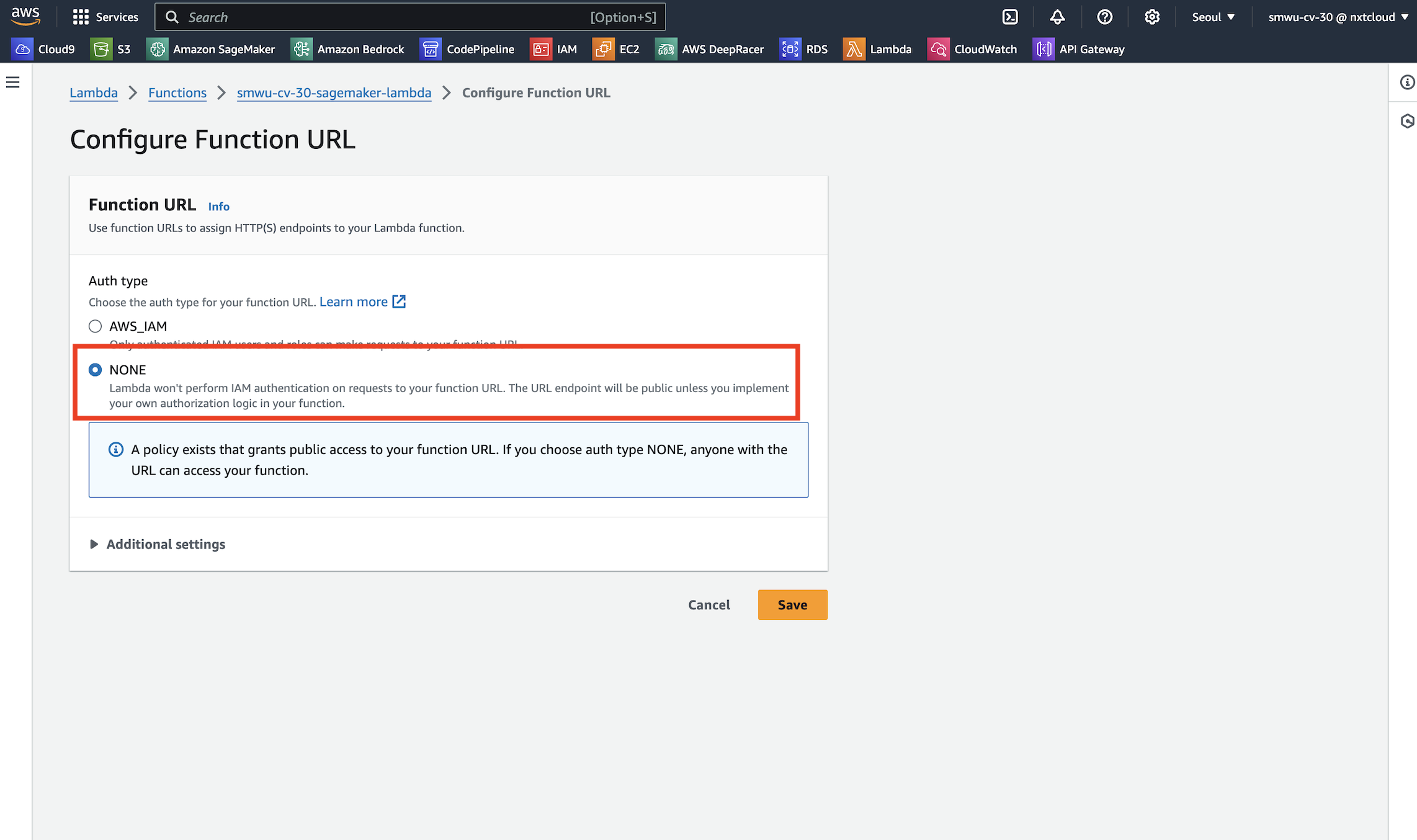
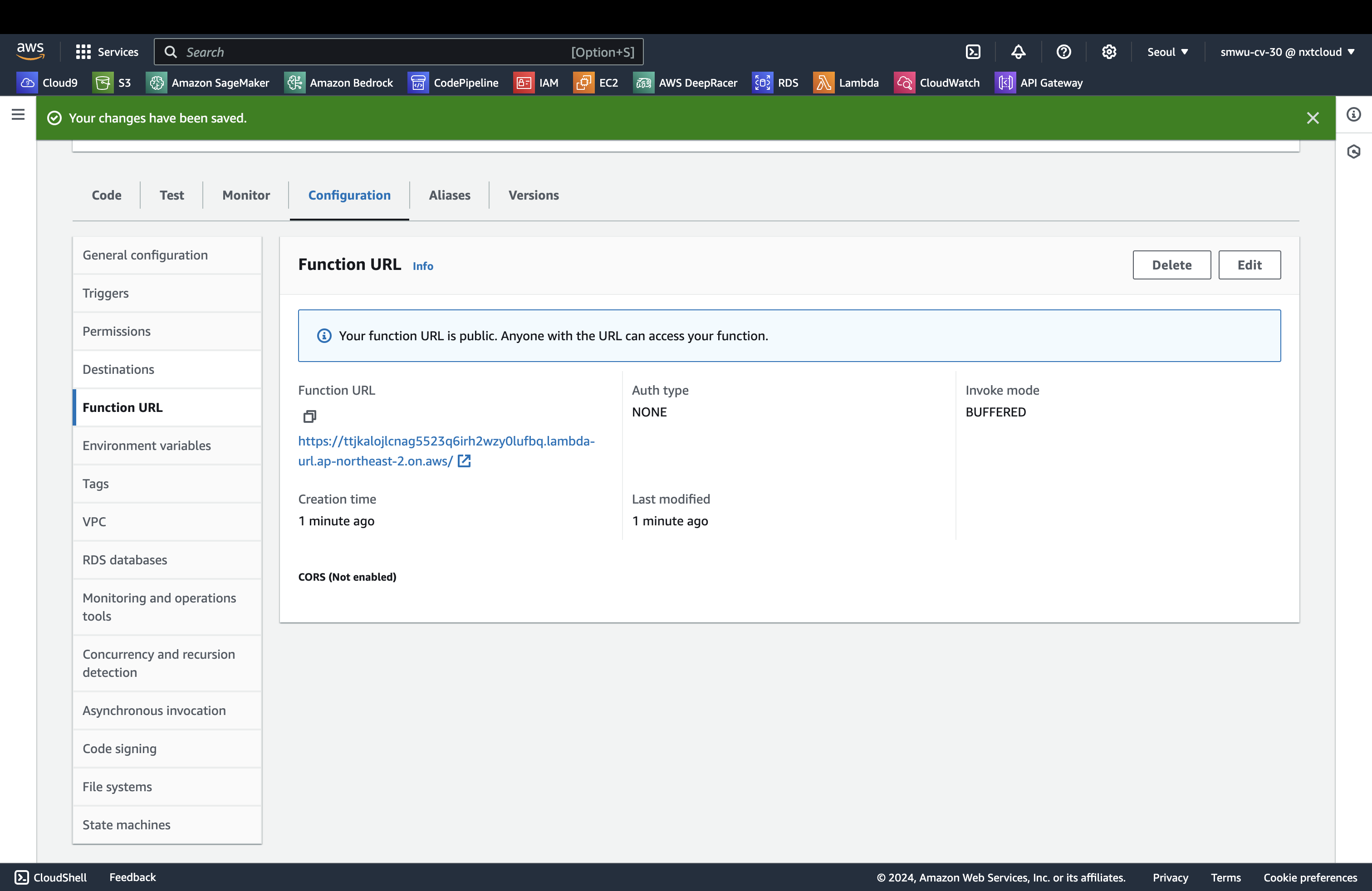
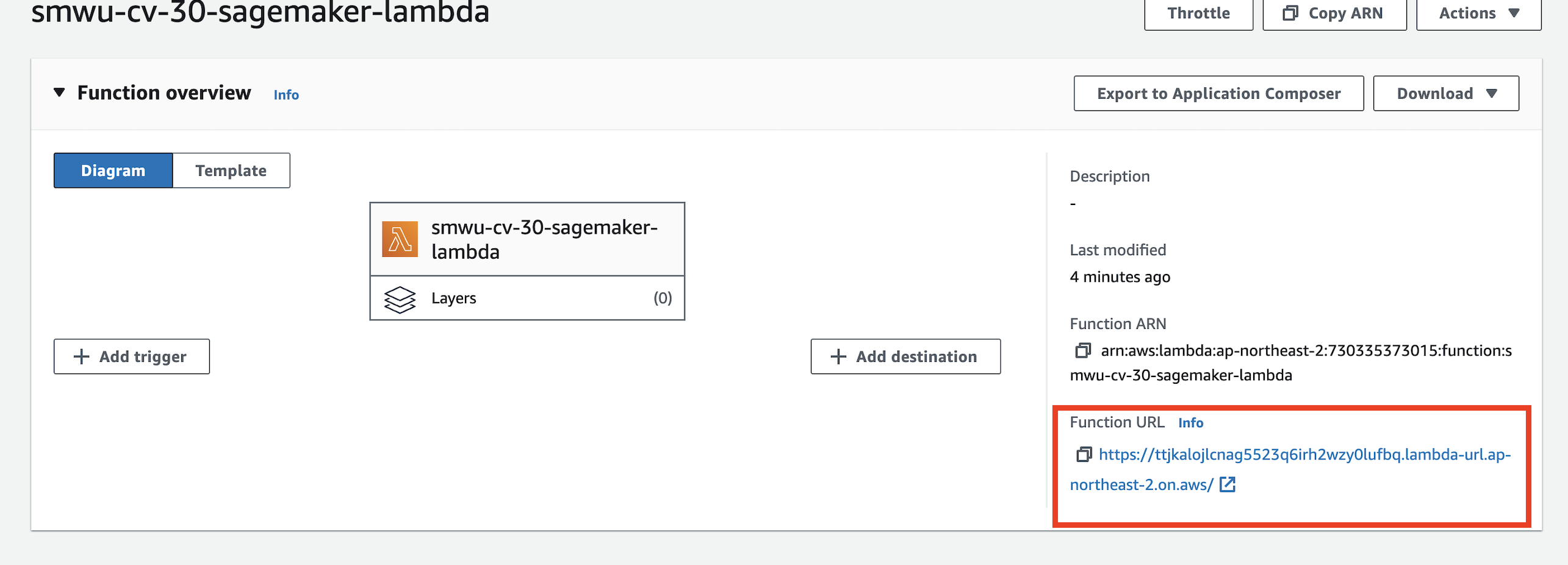
생성된 함수의 함수 URL 을 확인할 수 있습니다. 해당 URL을 별도로 저장합니다.
import os
import io
import boto3 # Python SDK for AWS. 람다 런타임에 기본적으로 제공
import json
import csv
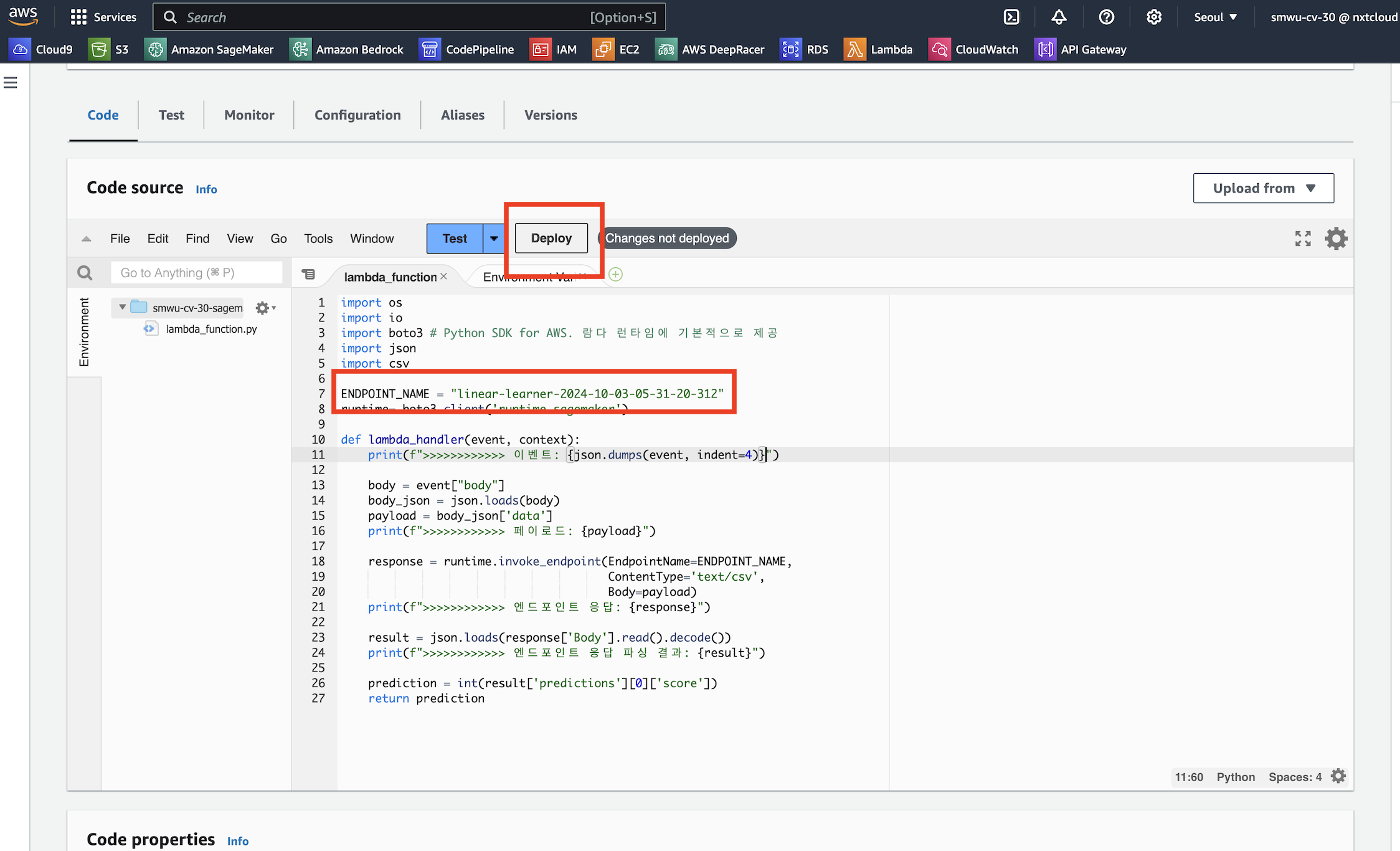
ENDPOINT_NAME = "여기에 엔드포인트 이름을 입력하세요"
runtime= boto3.client('runtime.sagemaker')
def lambda_handler(event, context):
print(f">>>>>>>>>>>> 이벤트: {json.dumps(event, indent=4)}")
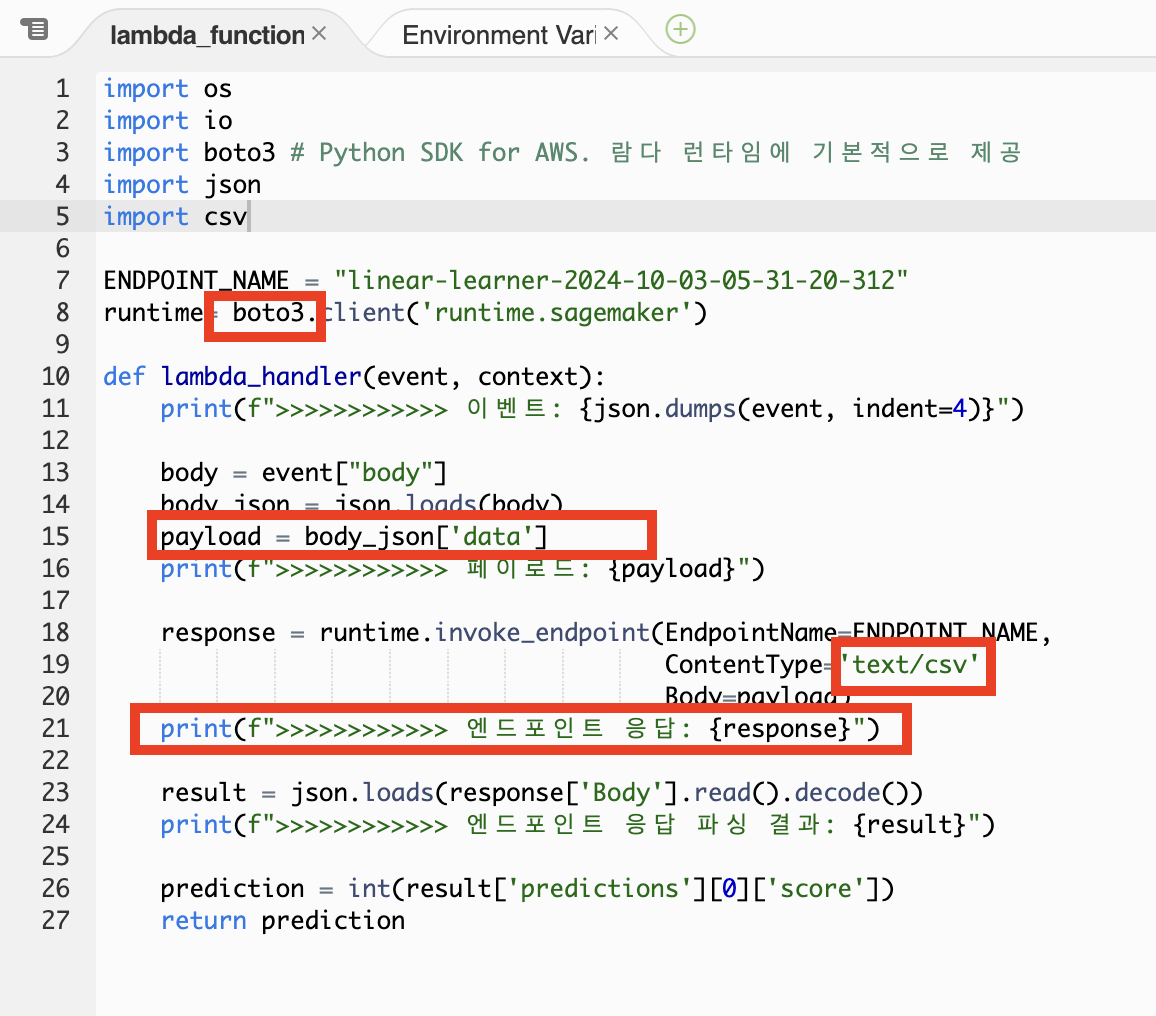
body = event["body"]
body_json = json.loads(body)
payload = body_json['data']
print(f">>>>>>>>>>>> 페이로드: {payload}")
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='text/csv',
Body=payload)
print(f">>>>>>>>>>>> 엔드포인트 응답: {response}")
result = json.loads(response['Body'].read().decode())
print(f">>>>>>>>>>>> 엔드포인트 응답 파싱 결과: {result}")
prediction = int(result['predictions'][0]['score'])
return prediction
Code 탭 선택 후 위 코드를 복사하여 넣어줍니다. 코드를 붙여넣기한 후에는 수정 사항을 반영하는 배포(Deploy) 버튼을 클릭합니다.
람다 함수에 POST 요청을 보내기 위해 AWS Cloud9을 사용합니다.
Cloud9 IDE에 app.py 파일 생성 후 아래 코드 복사 붙여넣기 합니다.
import json
import requests
LAMBDA_URL = "여기에 람다 함수 URL을 입력하세요"
example = { "data": "37, 1, 3, 140, 169, 0, 0, 200, 0, 0, 2, 0, 2" }
# example = { "data": "51, 0, 1, 144, 208, 1, 1, 169, 0, 0, 2, 2, 2" }
response = requests.post(LAMBDA_URL, json=example)
print(f"응답: ", response)
print(response.text)
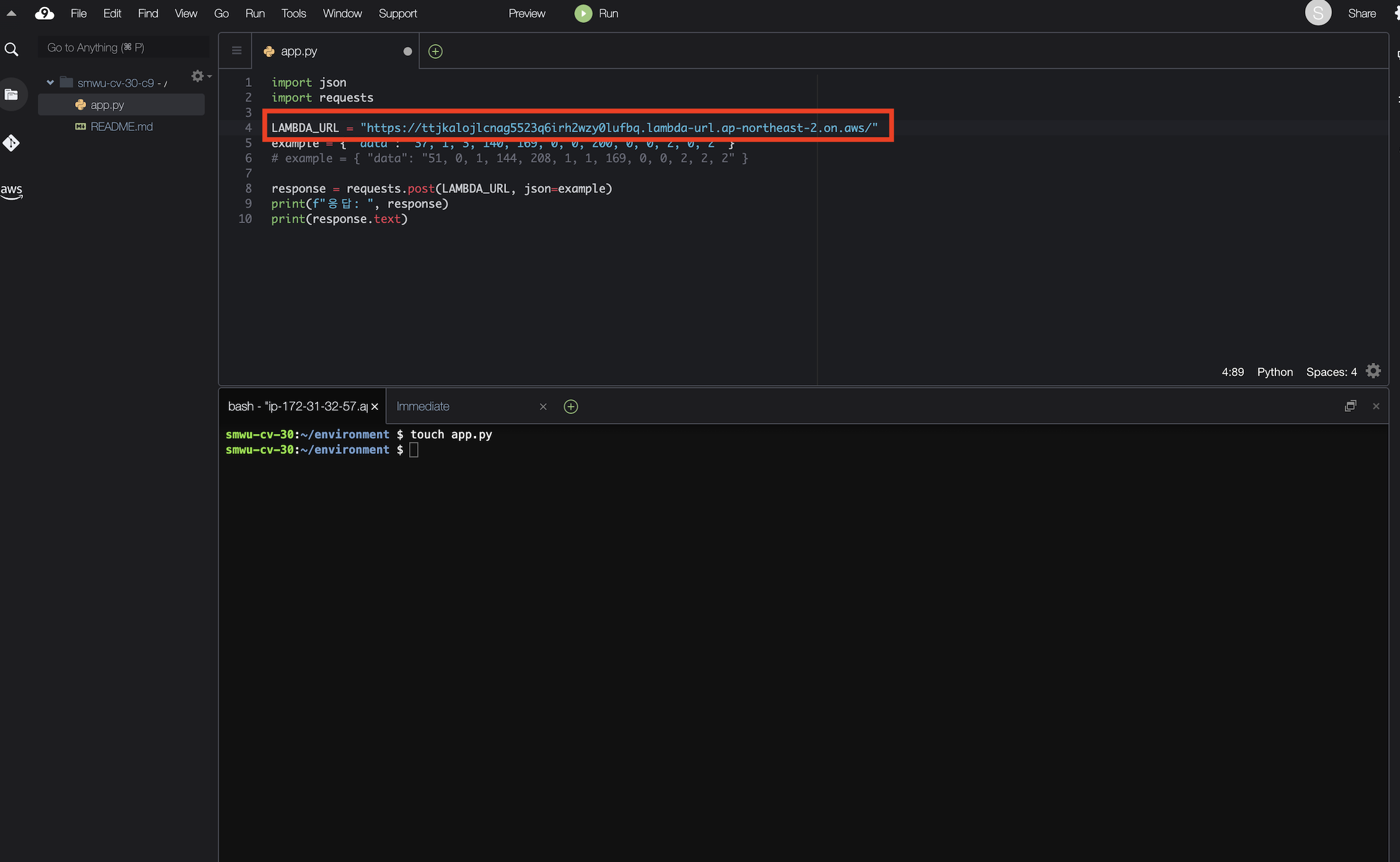
파일을 실행하면 HTTP 502: Bad Gateway 에러가 발생합니다.
해당 에러는 서버측 에러로 람다 함수가 적절한 권한(SageMaker Endpoint 호출)이 없기 때문에 발생하는 에러입니다.
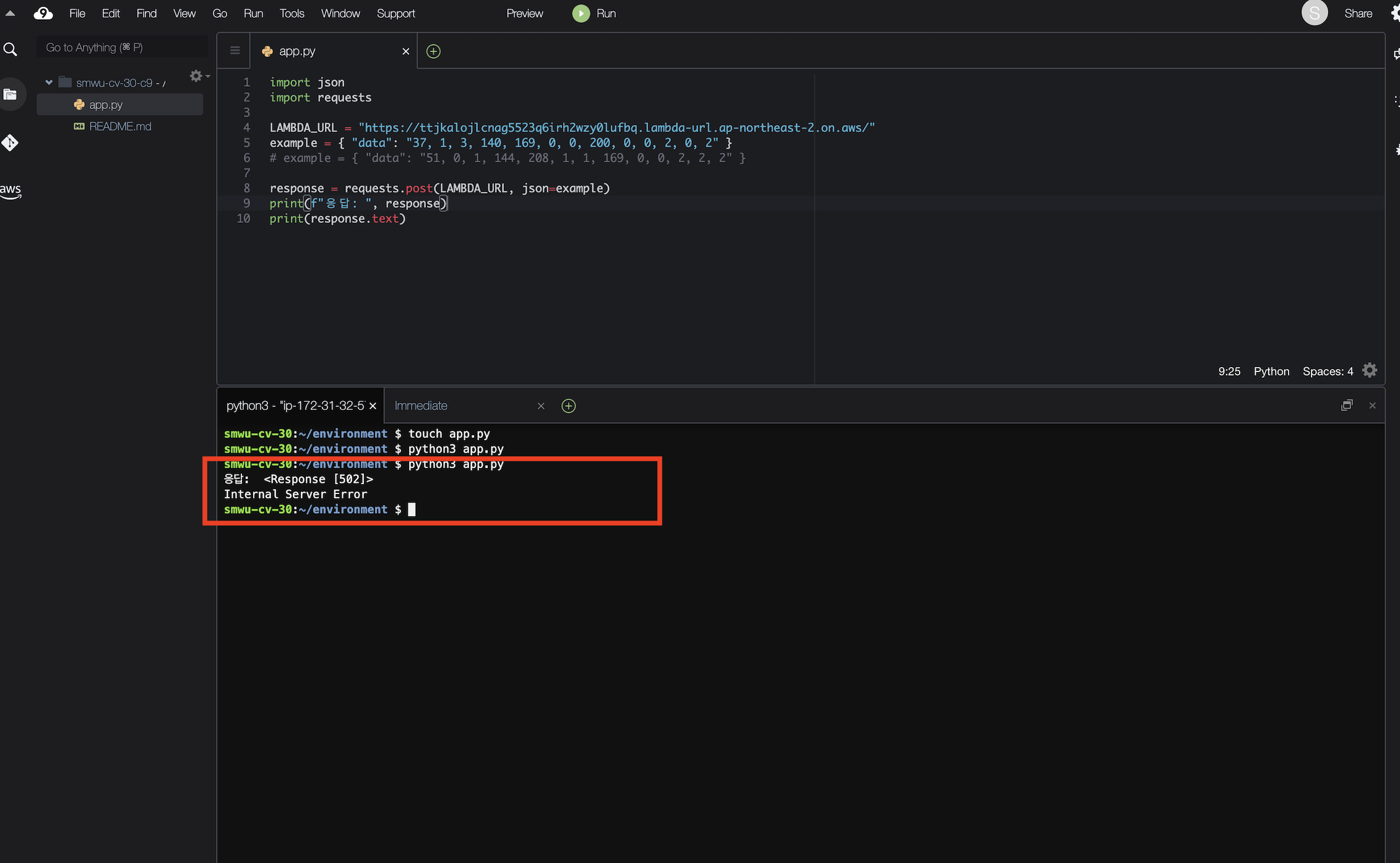
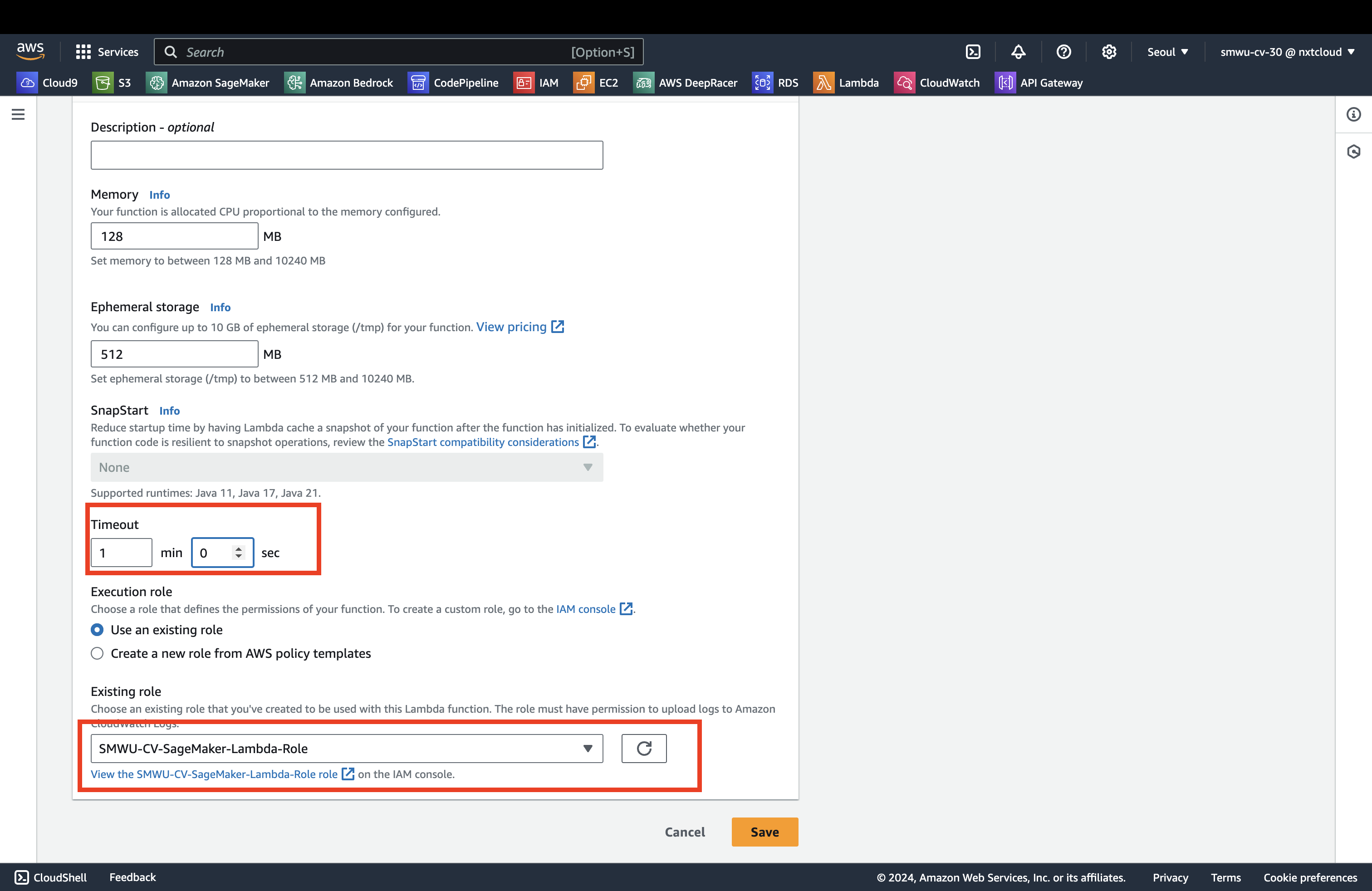
다시 Lambda Configuration 탭으로 돌아가서 람다 함수 권한을 부여해줍니다. Permission 선택 후 Edit 클릭하고 편집을 해줍니다.
Role과 람다 실행 시간을 상향으로 설정합니다.
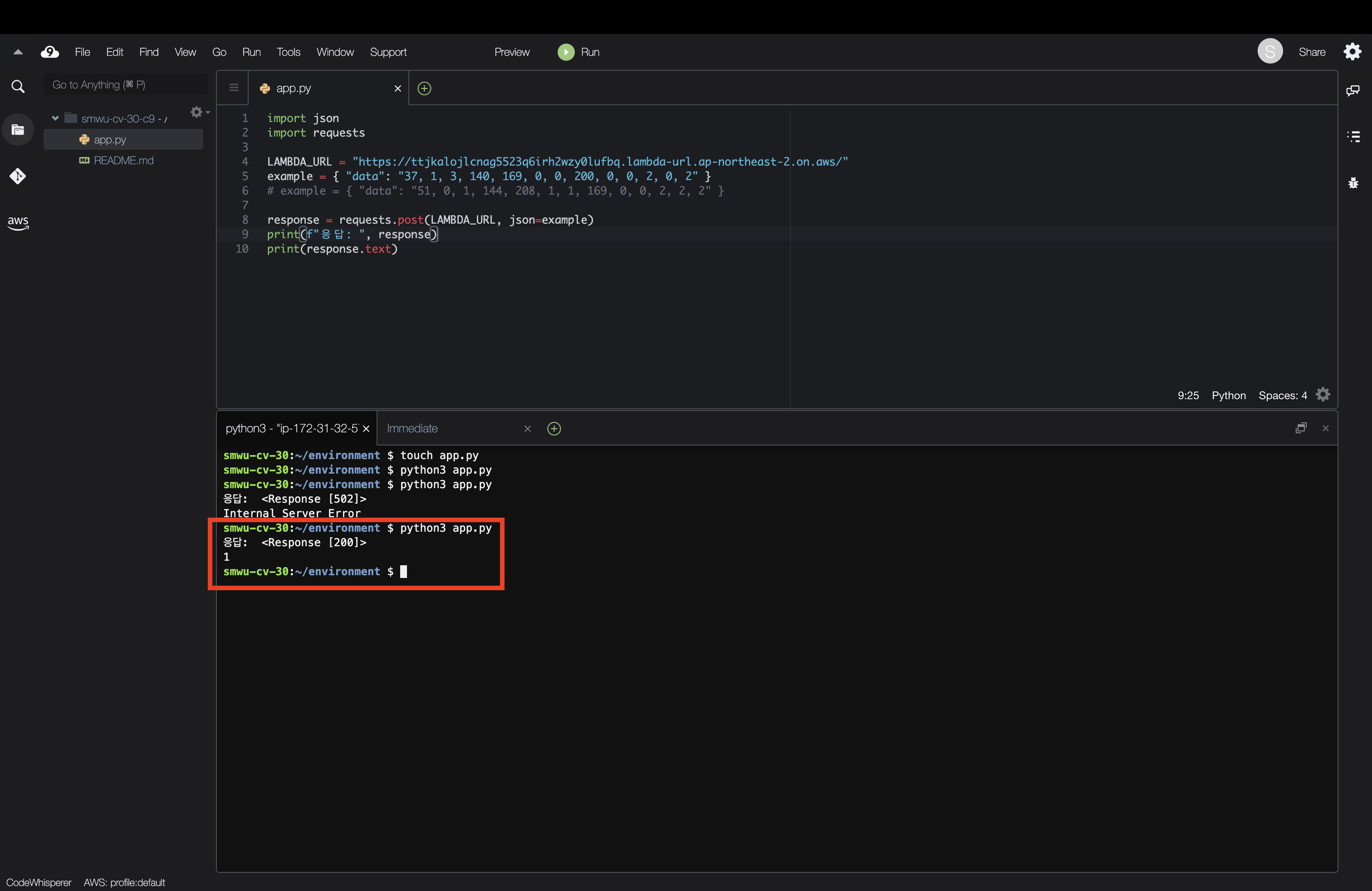
다시 Cloud9 에서 코드를 재실행 해줍니다. 파일을 실행하면 이번에는 성공적으로 HTTP 200 응답을 받을 수 있고 심장마비 가능성이 높은 1을 리턴하는 것을 확인할 수 있습니다.
'AI > computer vision' 카테고리의 다른 글
| [Amazon Rekognition] Facial Authentication (0) | 2024.10.05 |
|---|---|
| Image Processing Using OpenCV (1) | 2024.10.03 |